Rework of verbose
Verbose is my vocabulary web service to memorize and look up new and interesting english words. Since I’m continuously containerize my services , I stumpled across this service depending on nginx, php and mysql. Verbose was intended to be a non-fancy and simple project, so I rather thought about the requirements and reworked a proper docker-native solution than running a bunch of containers.
History
I started to read english books1 to improve my language skills. But as the amount of new words grew, it felt like reading progress slowed down continously due to repeated look ups and high amount of new words to learn.
At first I cached all the lookups in a text file, then only added interesting, elegant or notable words to lower the total amount. Later I built a web service that simply provides an form to add new words and showed a list of all words so far. A text file could’ve been enough, but you know, having a project with a real use-case gives a developer computer science student the feeling of doing something that matters rather than just implementing demos or theoretical/fictional use-cases.
There were tons of features that could be nice for the service. But the goal of this project was to focus on the main use-case and avoid edge case posoning. I had literally thousand of software projects in my developer life but only a hand full grew to something noteworthy or actually useful. Although it was hard to give up (or let’s say postpone) all the exciting ideas and just implement an MVP, the long-term experience of having a useful tool where time of use >> time of development was great.
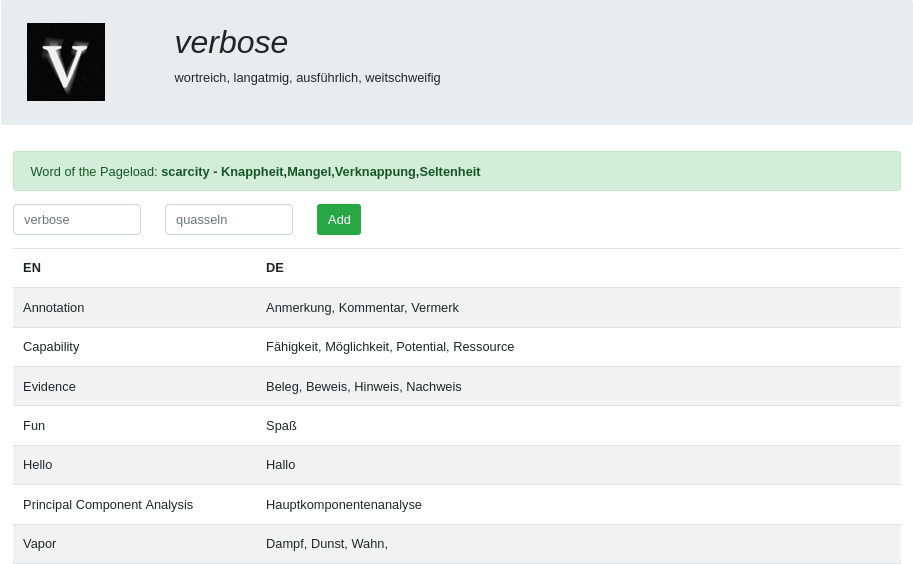
There were only two optional features added: word-of-the-pageload and count of words at the bottom.
Original setup
The web site was built with bootstrap to quickly create an appealing look without investing too much time with CSS. The backend was made with PHP providing the translations from the MariaDB database to the frontend and storing new once from the form secured with htaccess.
The backend only had two routes:
GET /: view web site with all translationsPOST add.php: add a new translation
The database schema was fairly simple:
CREATE TABLE `vocabulary` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`de` varchar(255) DEFAULT NULL,
`en` varchar(255) DEFAULT NULL,
`added` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
The old setup can be found here.
Reworked setup
The frontend remained the same. The backend was completely replaced with a containerized go binary providing the web site plus a REST-API for using the translations programatically. The relational database table was replaced with a simple data structure which is un-/marshalled2 to JSON and stored within a docker volume. Generally it is not a good idea to use a file-based storage backend for a public available web service when implemented naively. I/O is very time consuming compared by having the data in-memory or requesting a service that has it in-memory. But on average I view it once a day and add only one word per month. Reading the file only on start up and writing it only on adding a new word to get rid of a database server was a fair compromise.
Data structure:
type Translation struct {
Words []string `json:"words"`
}
type Vocabulary struct {
Entries map[string]Translation
}
Snipptet from the JSON file:
{
"Fun": { "words": [ "Spaß" ] },
"adorable": { "words": [ "bezaubernd", "liebenswert" ] },
"done": { "words": [ "fertig" ] },
"verbose": { "words": [ "quasseln" ] }
}
Routes:
- Web site:
GET /: view web site with all translationsPOST /new: add new translation
- REST-API:
GET /api/v1/words: get all wordsGET /api/v1/words/<en word: get a translation for a given english wordPOST /api/v1/words/<en word>: add new translation
- Hitchhiker’s Guide to the galaxy from Douglas Adams and Animal Farm by George Orwell
- un-/marshalling are the go equivalent of de-/serialization of data